准备工具
chrome浏览器、Web Scraper插件
操作步骤
抓取八步曲:
1.Chrome页面右键->检查->WebScraper
2.创建一个新站点 Create sitemap
3.输入站点名称(自定义)和网址(目标网址),点击Create sitemap的确认按钮。
4.新增选择器,点击Add new selector
5.选择器配置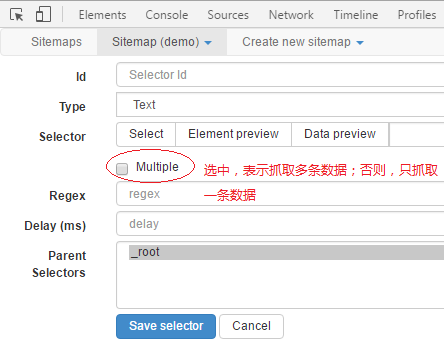
点击Select后,接着在目标网页中选择要抓取的信息。
例如要抓取本页面的所有回答的标题信息,依次点击同类型元素,这样本页面所有回答的标题都会自动被选择。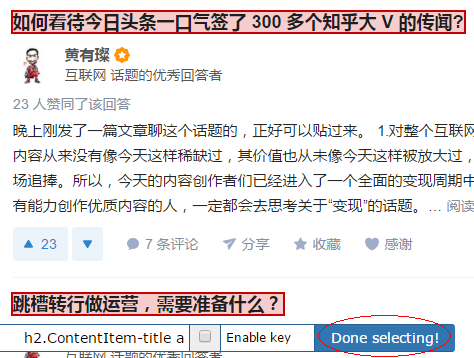
点击Done selecting,可以点击Element preview预览选中要抓取的数据是否正确。
设置delay,通常设置为500ms,有两方面原因:1.等待数据动态加载;2.网络比较卡,我们或者对方服务器网络比较卡时,需要过几百毫秒后页面才能加载完毕。
点击 Save selector。
6.抓取数据。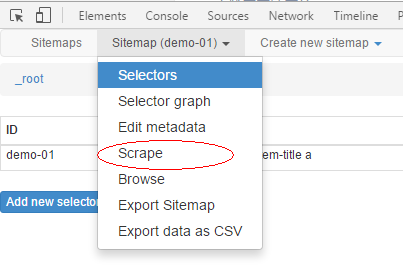
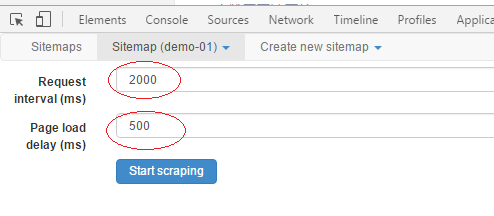
设置Request interval 请求间隔:2000ms
有两方面原因:1.如果访问频率过高会导致目标网站服务器负载过大,影响正常访问;2.访问频率过高会被目标网站的反爬虫机制检测到而加入黑名单。
设置Page load delay 页面加载延迟:500ms
1.等待数据动态加载;
2.网络比较卡,我们或者对方服务器网络比较卡。
点击Start scraping后,自动弹框开始抓取。
7.导出数据,可用excel进行编辑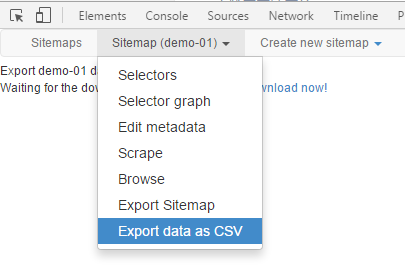
8.抓取规律的多页数据,点击Edit metadata设置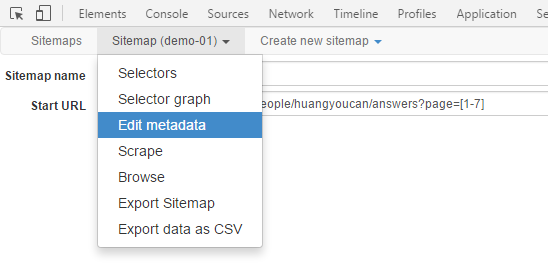
规律的多页数据分为两类:
1.类似知乎的 https://www.zhihu.com/people/huangyoucan/answers?page=1
要抓取多个页面,Start URL可以设置为 https://www.zhihu.com/people/huangyoucan/answers?page=[1-7]
2.类似豆瓣的 https://movie.douban.com/review/best/?start=0
要抓取多个页面,Start URL可以设置为https://movie.douban.com/review/best/?start=[0-100:20]