最近刚接手一个涉及个性化推荐的产品,由于在此之前我对个性化推荐完全不了解,因此上网搜寻入门书籍。各路大神纷纷推荐《推荐系统实践》这本书,读完之后顿感收获颇多。将书中精华整理成系列文章,本文是第二篇。
冷启动阶段
冷启动可采用的方式
- 在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起媒资的相关度表。
- 对于新加入的媒资,可以利用相关度推荐给喜欢过和它们相似的物品的用户。
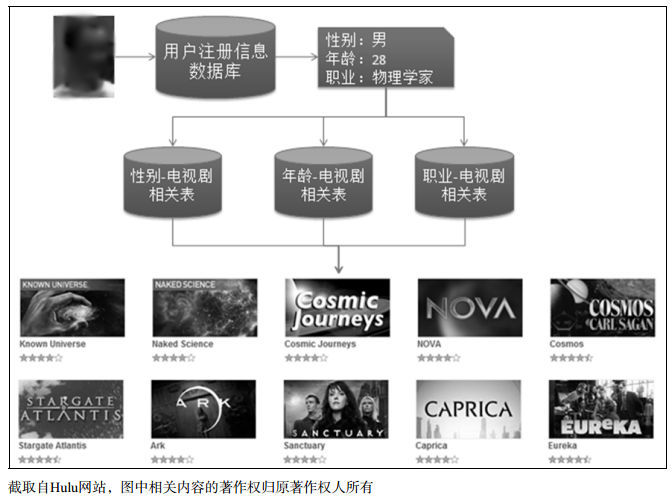
- 利用用户注册时的年龄、性别等数据做粗粒度的个性化推荐。案例详见下图。
- 使用非个性化推荐做冷启动,比如热播榜。
基于用户行为数据
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法。学术界对协同过滤算法进行了深入研究,提出了很多方法,比如基于邻域的方法(neighborhood-based)、 隐语义模型(latent factor model)、 基于图的随机游走算法(random walk on graph)等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法。
- 基于用户的协同过滤算法 这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
- 基于物品的协同过滤算法 这种算法给用户推荐和他之前喜欢的物品相似的物品。
下面将主要介绍基于领域的方法,在最后简单介绍隐语义模型。
基于领域的方法
基于用户的协同过滤算法
每年新学期开始,刚进实验室的师弟总会问师兄相似的问题,比如“我应该买什么专业书啊”、“我应该看什么论文啊”等。这个时候,师兄一般会给他们做出一些推荐。这就是现实中个性化推荐的一种例子。在这个例子中,师弟可能会请教很多师兄,然后做出最终的判断。师弟之所以请教师兄,一方面是因为他们有社会关系,互相认识且信任对方,但更主要的原因是师兄和师弟有共同的研究领域和兴趣。那么,在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
从上面的描述中可以看到,基于用户的协同过滤算法主要包括两个步骤。
- 找到和目标用户兴趣相似的用户集合。
- 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
基于物品的协同过滤算法
基于物品的协同过滤(item-based collaborative filtering)算法是目前业界应用最多的算法。无论是亚马逊网,还是Netflix、 Hulu、 YouTube,其推荐算法的基础都是该算法。
基于物品的协同过滤算法(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。比如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过, ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
基于物品的协同过滤算法主要分为两步。
- 计算物品之间的相似度。
- 根据物品的相似度和用户的历史行为给用户生成推荐列表。
案例:
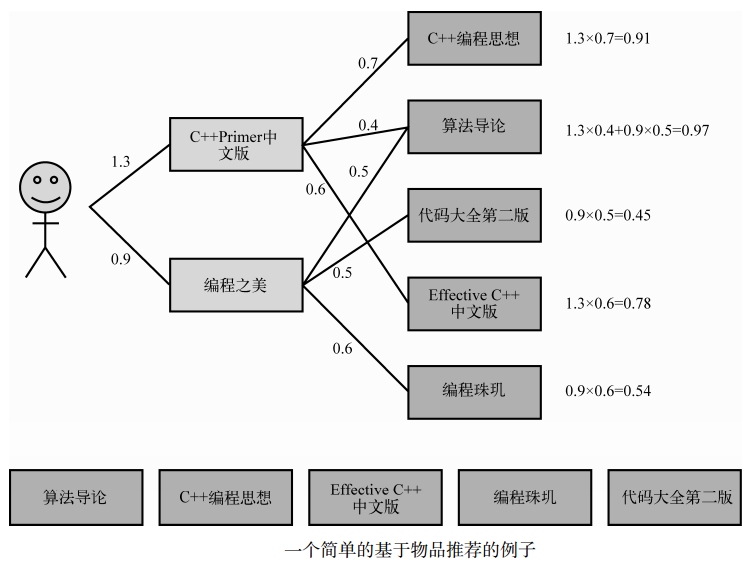
下图是一个基于物品推荐的简单例子。该例子中,用户喜欢《C++ Primer中文版》和《编程之美》两本书。然后ItemCF会为这两本书分别找出和它们最相似的3本书,然后根据公式的定义计算用户对每本书的感兴趣程度。比如, ItemCF给用户推荐《算法导论》,是因为这本书《C++Primer中文版》相似,相似度为0.4,而且这本书也和《编程之美》相似,相似度是0.5。考虑到用户对《C++ Primer中文版》的兴趣度是1.3,对《编程之美》的兴趣度是0.9,那么用户对《算法导论》的兴趣度就是1.3 × 0.4 + 0.9×0.5 = 0.97。
隐语义模型
隐语义模型是最近几年推荐系统领域最为热门的研究话题,它的核心思想是通过隐含特征
(latent factor)联系用户兴趣和物品。可以对书和物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
总结一下,这个基于兴趣分类的方法大概需要解决3个问题。
- 如何给物品进行分类?
- 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
- 对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在一个类中的权重?
初级做法
- 编辑人员给物品分类。以图书为例,每本书出版时,编辑都会给书一个分类,遵循中国图书分类法。电影、电视剧也类似。
- 用户初次进入系统时,选择偏好;
- 根据用户的偏好,推荐该类下的视频,按热度进行推荐。
更进一层
由编辑人员给物品分类的方式有以下问题:
- 编辑的意见不能代表各种用户的意见;
- 编辑很难控制分类的粒度;例如《数据挖掘导论》的粗粒度分类可能属于计算机技术,但在细粒度的分类可能属于数据挖掘。
- 编辑很难给一个物品多个分类;
- 编辑很难确定一个物品在该分类下的权重;当一个物品属于多个分类时,那么该物品在不同分类下有不同的权重。例如《唐人街探案2》同时属于喜剧、动作、悬疑、剧情、情感等多个分类下,这部电影的喜剧成分远高于情感成分,因此在喜剧分类和情感分类下的权重应该是不一样的。
为了解决上面的问题,研究人员提出从数据出发自动找到那些类,然后进行个性化推荐。隐含语义分析技术因为采取基于用户行为统计的自动聚类,较好了解决了上面的问题。
- 如果两个物品被很多用户同时喜欢,那么这两个物品就很有可能属于同一个类。
- 隐含语义分析技术允许我们指定最终有多少个分类,这个数字越大,分类的粒度就会越细,反正分类粒度就越粗。
- 隐含语义分析技术会计算出物品属于每个类的权重,因此每个物品都不是硬性地被分到某一个类中。
- 隐含语义分析技术给出的每个分类都不是同一个维度的,它是基于用户的共同兴趣计算出来的,如果用户的共同兴趣是某一个维度,那么LFM给出的类也是相同的维度。
- 隐含语义分析技术可以通过统计用户行为决定物品在每个类中的权重,如果喜欢某个类的用户都会喜欢某个物品,那么这个物品在这个类中的权重就可能比较高。
基于用户标签数据
拿到了用户标签行为数据,相信大家都可以想到一个最简单的个性化推荐算法。这个算法的描述如下所示。
- 统计每个用户最常用的标签。
- 对于每个标签,统计被打过这个标签次数最多的物品。
- 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
利用上下文信息
时间上下文
时间是一种重要的上下文信息,对用户兴趣有着深入而广泛的影响。一般认为,时间信息对
用户兴趣的影响表现在以下几个方面。
- 用户兴趣是变化的,我们这里提到的用户兴趣变化是因为用户自身原因发生的变化。比如随着年龄的增长,用户小时候喜欢看动画片,长大了喜欢看文艺片。一位程序员随着工作时间的增加,逐渐从阅读入门书籍过渡到阅读专业书籍。一个人参加工作了,工作后的兴趣和学生时代的兴趣相比发生了变化。那么,如果我们要准确预测用户现在的兴趣,就应该关注用户最近的行为,因为用户最近的行为最能体现他现在的兴趣。当然,考虑用户最近的兴趣只能针对渐变的用户兴趣,而对突变的用户兴趣很难起作用,比如用户突然中奖了。
- 物品也是有生命周期的,一部电影刚上映的时候可能被很多人关注,但是经久不衰的电影是很少的,很多电影上映后不久就被人们淡忘了。
最近最热门(非个性化)
基于热度的推荐,如果不考虑时间,系统给用户推荐的就是历史热门度,这种方式不能体现一段时间内用户群的兴趣。因此,加入时间T,就可以给用户推荐最近最热门的电影。
时间上下文相关的用户协同过滤
前面基于用户的协同过滤算法的基本思想:给用户推荐和他兴趣相似的其他用户喜欢的物品。从这个基本思想出发,可以在以下两个方面利用时间信息改进UserCF算法。
- 用户兴趣相似度 两个用户兴趣相似是因为他们喜欢相同的物品,或者对相同的物品产生过行为。但是,如果两个用户同时喜欢相同的物品,那么这两个用户应该有更大的兴趣相似度。比如用户A在2006年对C++感兴趣,在2007年对Java感兴趣,用户B在2006年对Java感兴趣, 2007年对C++感兴趣,而用户C和A一样,在2006年对C++感兴趣,在2007年对Java感兴趣。那么,根据UserCF,用户A和用户B的兴趣相似度等于用户A和用户C的兴趣相似度。但显然,在实际世界,我们会认为用户A和C的兴趣相似度要大于用户A和B。
- 相似兴趣用户的最近行为 在找到和当前用户u兴趣相似的一组用户后,这组用户最近的兴趣显然相比这组用户很久之前的兴趣更加接近用户u今天的兴趣。也就是说,我们应该给用户推荐和他兴趣相似的用户最近喜欢的物品。在新闻推荐系统中,时间信息在UserCF中的作用非常明显。假设我们今天要给一个NBA篮球迷推荐新闻。首先,我们需要找到一批和他一样的NBA迷,然后找到这批人在当前时刻最近阅读最多的新闻推荐给当前用户,而不是把这批人去年阅读的新闻推荐给当前用户,因为他们去年阅读最多的新闻在现在看显然过期了。
时间上下文相关的物品协同过滤
基于物品(item-based)的个性化推荐算法是商用推荐系统中应用最广泛的,从前面的讨论可以看到,该算法由两个核心部分构成:
- 计算物品之间的相似度。
- 根据物品的相似度和用户的历史行为给用户生成推荐列表。
时间信息在上面两个核心部分中都有重要的应用,这体现在两种时间效应上。 - 物品相似度 用户在相隔很短的时间内喜欢的物品具有更高相似度。以电影推荐为例,用户今天看的电影和用户昨天看的电影其相似度在统计意义上应该大于用户今天看的电影和用户一年前看的电影的相似度。
- 在线推荐 用户近期行为相比用户很久之前的行为,更能体现用户现在的兴趣。因此在预测用户现在的兴趣时,应该加重用户近期行为的权重,优先给用户推荐那些和他近期喜欢的物品相似的物品。
地点上下文
这部分内容不是重点,以后再补充!
利用社交网络数据
一般来说,有3种不同的社交网络数据。
- 双向确认的社交网络数据 在以Facebook和人人网为代表的社交网络中,用户A和B之间形成好友关系需要通过双方的确认。因此,这种社交网络一般可以通过无向图表示。
- 单向关注的社交网络数据 在以Twitter和新浪微博为代表的社交网络中,用户A可以关注用户B而不需要得到用户B的允许,因此这种社交网络中的用户关系是单向的,可以通过有向图表示。
- 基于社区的社交网络数据 还有一种社交网络数据,用户之间并没有明确的关系,但是这种数据包含了用户属于不同社区的数据。比如豆瓣小组,属于同一个小组可能代表了用户兴趣的相似性。或者在论文数据集中,同一篇文章的不同作者也存在着一定的社交关系。或者是在同一家公司工作的人,或是同一个学校毕业的人等。
基于社交网络的推荐
给用户推荐好友喜欢的物品。大体思路如下:
- 获取用户的好友列表以及行为数据;
- 统计好友对物品的兴趣度;
- 根据物品兴趣度推荐给用户;
这种方式的推荐精准度不高,因为用户的好友关系不是基于共同兴趣产生的,所以用户好友的兴趣往往和用户的兴趣并不一致。比如,我们和自己父母的兴趣往往就差别很大。
利用社交网络给用户推荐好友
基于内容的好友推荐
我们可以给用户推荐和他们有相似内容属性的用户作为好友。下面给出了常用的内容属性。
- 用户人口统计学属性,包括年龄、性别、职业、毕业学校和工作单位等。
- 用户的兴趣,包括用户喜欢的物品和发布过的言论等。
- 用户的位置信息,包括用户的住址、 IP地址和邮编等。
基于共同兴趣的好友推荐
共同兴趣可以从以下几个方面考虑:
- 用户喜欢相同的物品,则认为他们有相同的兴趣;
- 用户有相同的兴趣标签;
基于社交网络的好友推荐
给用户推荐好友的好友。